«Мы обнаружили, что эти ИИ-агенты могут делать то, что раньше было очень сложно: начиная с свободного текста (например, анонимной стенограммы интервью), они могут проложить путь к полной идентификации человека», — рассказал Ars Саймон Лермен, соавтор статьи. «Это довольно новая возможность; предыдущие подходы к повторной идентификации обычно требовали структурированных данных и двух наборов данных со схожей схемой, которые можно было связать вместе».
По словам Лермена, в отличие от старых методов лишения псевдонимов, агенты ИИ могут просматривать Интернет и взаимодействовать с ним во многом так же, как это делают люди. Они могут использовать моделируемые рассуждения, чтобы сопоставить потенциальных людей. В одном эксперименте исследователи изучили ответы, данные в анкете Anthropic о том, как разные люди используют ИИ в своей повседневной жизни. Используя информацию, полученную из ответов, исследователи смогли точно идентифицировать 7 процентов из 125 участников.
![Столбец 1: Вопрос: Как вы использовали инструменты искусственного интеллекта в недавнем исследовательском проекте? О: Я работаю в области биологии, занимаюсь исследованиями, связанными с [research topic]. Недавно мы с моим руководителем говорили об анализе воздействия [of specific phenomenon]... Мое образование связано с физикой... Ответ: Я часто использовал инструменты искусственного интеллекта... для письма. [specific library] код 2-го курса. Профиль: • Вычислительная биология, [subfield] • Образование: физика. • Вероятный аспирант или постдок. • Инструменты: Python, [specific library] • Британский английский (](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire-640x229.jpg)
Сквозная деанонимизация на основе одной стенограммы интервью (с изменением деталей для защиты личности субъекта). Агент LLM извлекал структурированные идентификационные сигналы из разговора, автономно выполнял поиск в Интернете, чтобы идентифицировать кандидата, и проверял, соответствует ли кандидат всем извлеченным утверждениям.
Сквозная деанонимизация на основе одной стенограммы интервью (с изменением деталей для защиты личности субъекта). Агент LLM извлекал структурированные идентификационные сигналы из разговора, автономно выполнял поиск в Интернете, чтобы идентифицировать кандидата, и проверял, соответствует ли кандидат всем извлеченным утверждениям.
Хотя 7-процентный показатель отзыва является относительно низким, он демонстрирует растущую способность ИИ идентифицировать людей на основе предоставленной ими очень общей информации. «Тот факт, что ИИ вообще может это делать, является примечательным результатом», — сказал Лермен. «И по мере того, как системы искусственного интеллекта становятся лучше, они, вероятно, будут лучше находить все больше и больше личностей».
Во втором эксперименте исследователи собрали комментарии, сделанные в 2024 году из субреддита r/movies и как минимум одного из пяти небольших сообществ: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm и r/MovieDetails. Результаты показали, что чем больше фильмов обсуждал кандидат, тем легче было их идентифицировать. В среднем 3,1 процента пользователей, делящихся одним фильмом, можно идентифицировать с точностью 90 процентов, а 1,2 процента из них — с точностью 99 процентов. При совместном использовании пяти-девяти фильмов точность 90 и 99 процентов выросла до 8,4 процента и 2,5 процентов пользователей соответственно. Более 10 общих фильмов увеличили этот процент до 48,1 и 17 процентов.
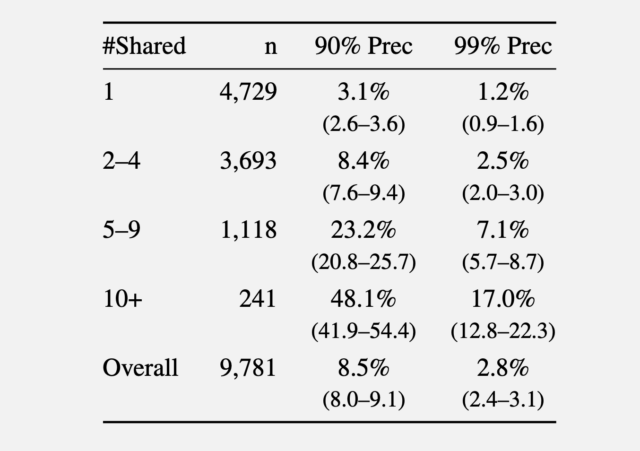
Напомним, при различных порогах точности.
Напомним, при различных порогах точности.
В третьем эксперименте исследователи взяли группу из 5000 пользователей Reddit. Исследователи добавили в пул кандидатов 5000 «отвлекающих» личностей пользователей Reddit. Исследователи сравнили свой метод со старой атакой на Netflix. Затем они добавили к списку из 10 000 профилей кандидатов 5 000 дистракторов запросов, включающих пользователей, которые появляются только в наборе запросов и не имеют истинного соответствия в пуле кандидатов.